Monocular video
Stereo video (Anaglyph 3D)

We tackle the problem of monocular-to-stereo video conversion and propose a novel architecture for inpainting and refinement of the warped right view obtained by depth-based reprojection of the input left view. We extend the Stable Video Diffusion (SVD) model to utilize the input left video, the warped right video, and the disocclusion masks as conditioning input to generate a high-quality right camera view. In order to effectively exploit information from neighboring frames for inpainting, we modify the attention layers in SVD to compute full attention for discoccluded pixels. Our model is trained to generate the right view video in an end-to-end manner without iterative diffusion steps by minimizing image space losses to ensure high-quality generation. Our approach outperforms previous state-of-the-art methods, being ranked best \(2.6\times\) more often than the second-place method in a user study, while being \(6\times\) faster.
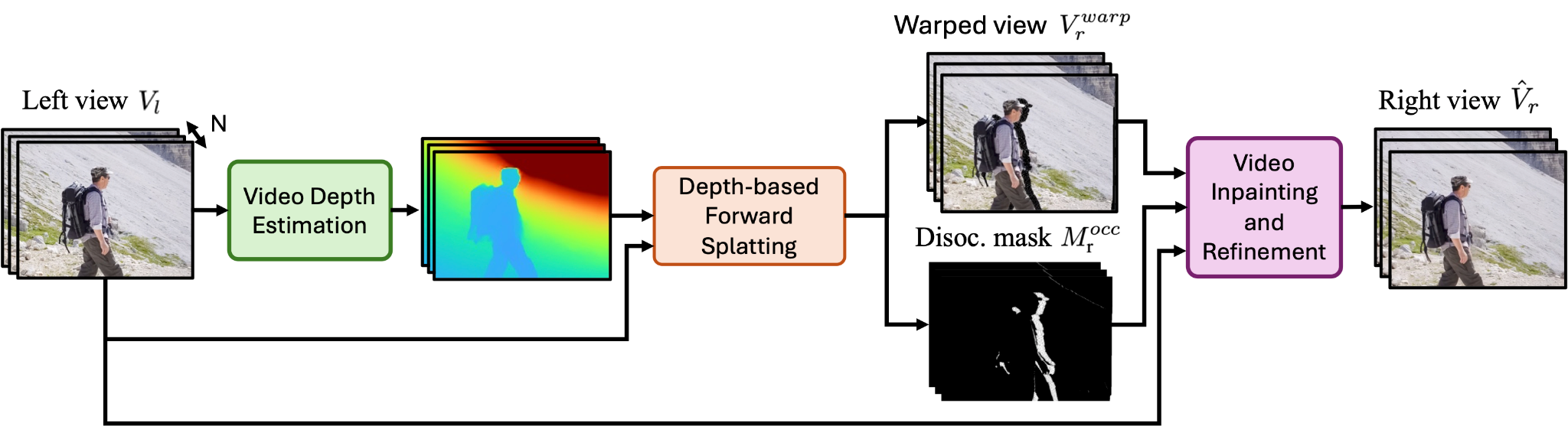
Given an input monocular video \(V_l\), which serves as the left camera view, we first estimate per-pixel depth using an off-the-shelf depth estimation model. Using the estimated depth, we then warp the input video to obtain a right camera view, producing both the warped right view \(V_r^\text{warp}\) and a disocclusion mask \(M^\text{occ}_r\). The input video, the warped view, and the disocclusion mask are then passed to our video inpainting and refinement module to generate the final right view \(\hat{V}_r\) in a single diffusion step.
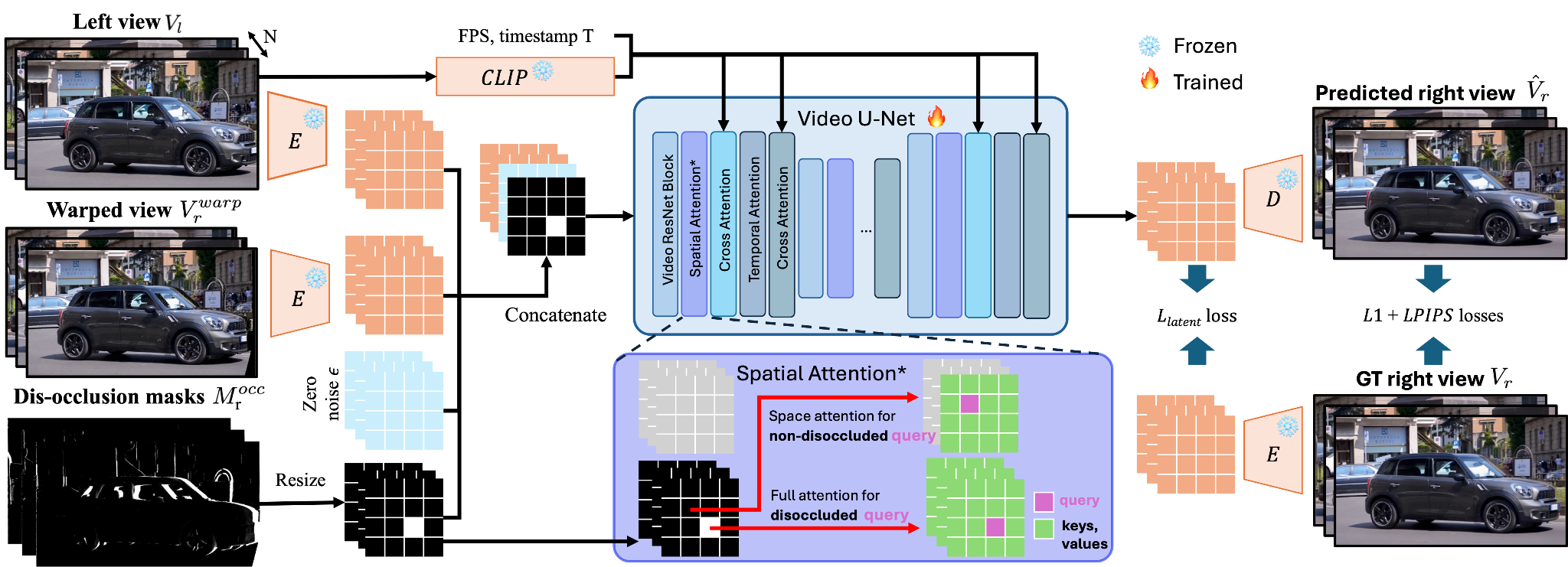
We introduce an efficient end-to-end model for generating a high-quality right video from the warped right video. Our model inpaints the discoccluded regions in the warped right view, and corrects possible artifacts introduced by warping errors. We base our model on a strong video diffusion model, namely Stable Video Diffusion (SVD), to benefit from learned video priors. The model takes the VAE encodings of the input left view \(V_l\), warped right view \(V_r^\text{warp}\), and the disocclusion mask \(M^\text{occ}_r\) as conditioning to the Video U-Net. The latent encodings of the refined right view are then generated in a single denoising step, and then decoded by the VAE Decoder to generate the output right video. In order to effectively utilize the information from neighboring frames for inpainting, we extend the spatial attention layer in SVD to compute full attention for the disoccluded tokens. The model is trained end-to-end by minimizing image space and latent space losses.
Input: Left-eye video
Generated: Right-eye video
Generated: Anaglyph 3D
Input: Left-eye video
Generated: Right-eye video
Generated: Anaglyph 3D
Input: Left-eye video
Generated: Right-eye video
Generated: Anaglyph 3D
We compare our method to the recent state-of-the-art monocular-to-stereo conversion models SVG and StereoCrafter. For more results, please click left and right arrows below.
We also conduct a user study to evaluate the quality of the generated right views, as well as a run-time analysis. Participants were asked to rank the quality of the generated videos from 1 (best) to 4 (worst), considering factors such as temporal consistency, image quality (i.e., sharpness), and absence of artifacts. Run-times are measured using an A100 GPU on 512x512 videos with 16 frames.
| Method | Denoising steps | Average rank ↓ | Latency (s) ↓ |
|---|---|---|---|
| SVG | 50 steps | 2.88 | 1270.4 |
| StereoCrafter | 25 steps | 2.05 | 12.2 |
| StereoCrafter | 1 step | 3.46 | 2.4 |
| M2SVid (ours) | 1 step | 1.43 | 2.1 |
Our method significantly outperforms StereoCrafter and SVG with an average rank of 1.43. Our method also achieves a 6x and 635x speed-up compared to StereoCrafter with 25 steps and SVG respectively.

Our approach can effectively preserve the high-frequency information from the input video and generate high-quality right views.
@article{shvetsova2025m2svid,
author = {Shvetsova, Nina and Bhat, Goutam and Truong, Prune and Kuehne, Hilde and Tombari, Federico},
title = {M2SVid: End-to-End Inpainting and Refinement for Monocular-to-Stereo Video Conversion},
year = {2025}
}